Plus de données ont été créées en 2011 que dans toute l’histoire de l’humanité. La data, tout le monde en parle ces dernières années et le terme Big Data, qui a fait le buzz en 2012, s’est avéré être, quelques années plus tard, un enjeu de taille. Objets connectés, réseaux sociaux, Open Data,… : les sources de données se multiplient, faisant miroiter aux assureurs une connaissance fine des attentes, comportement et propension au risque des assurés et des prospects. La promesse est belle : nouveaux produits et services innovants, individualisation croissante et accès à des modèles prédictifs. Pourtant, l’exploitation de ces données n’est pas aisée, et ce pour des raisons juridiques, techniques ou encore économiques. De ce fait, l’intérêt des sources de données est variable. Pour mettre en œuvre la data science, faut-il tenir compte de toutes les sources de données ou opérer une sélection ?
Un actif informationnel à valoriser
Les bases de données disponibles sont toujours plus nombreuses et riches. Cependant, le secteur assuranciel souffre d’une insuffisance d’informations. En effet, dans le modèle traditionnel, l’assureur est incapable de déterminer pourquoi deux personnes de la même catégorie socioprofessionnelle agissent différemment. Les modèles actuariels de tarification tiennent souvent sur 4 ou 5 indicateurs. Or, pour tirer des renseignements à valeur ajoutée, il convient d’identifier des signaux faibles en croisant plusieurs sources de données afin de trouver les bonnes corrélations et pouvoir adapter les prestations.
Avant de se lancer, il est donc nécessaire d’avoir une vision claire de la démarche à suivre et les objectifs métiers du projet. Quel est l’enjeu de la transformation Big Data ? Par où commencer ? Et quel est le chemin à suivre pour générer de la plus-value ? Et surtout, aller jusqu’au bout de la démarche et ne pas avorter le projet en cours de route.
L’assurance, un secteur en pleine mutation…
Le secteur de l’assurance entame un virage sans précèdent. Les pressions réglementaires, l’évolution des comportements client, les avancées technologiques ainsi que les changements socioéconomiques poussent l’assurance à chercher de nouveaux relais de croissance et font émerger plusieurs questionnements sur sa proposition de valeur, son rôle social et économique. Au-delà du digital, la valorisation des données est au cœur de la solution et représente un levier pour cette transformation inévitable.
Dans une réflexion transverse autour des données, le Big Data se présente comme une opportunité pour reconsidérer toute la chaîne de valeur assurantielle en allant de la conception de nouveaux produits et la connaissance des clients jusqu’à la gestion des sinistres et la proposition de nouveaux services. Dans ce contexte, le repositionnement passe par une compréhension des besoins du client au sens large et non pas garantie par garantie. Ci-dessous, des exemples d’impacts de la valorisation des données sur les fonctions de la chaîne de valeur de l’assurance.
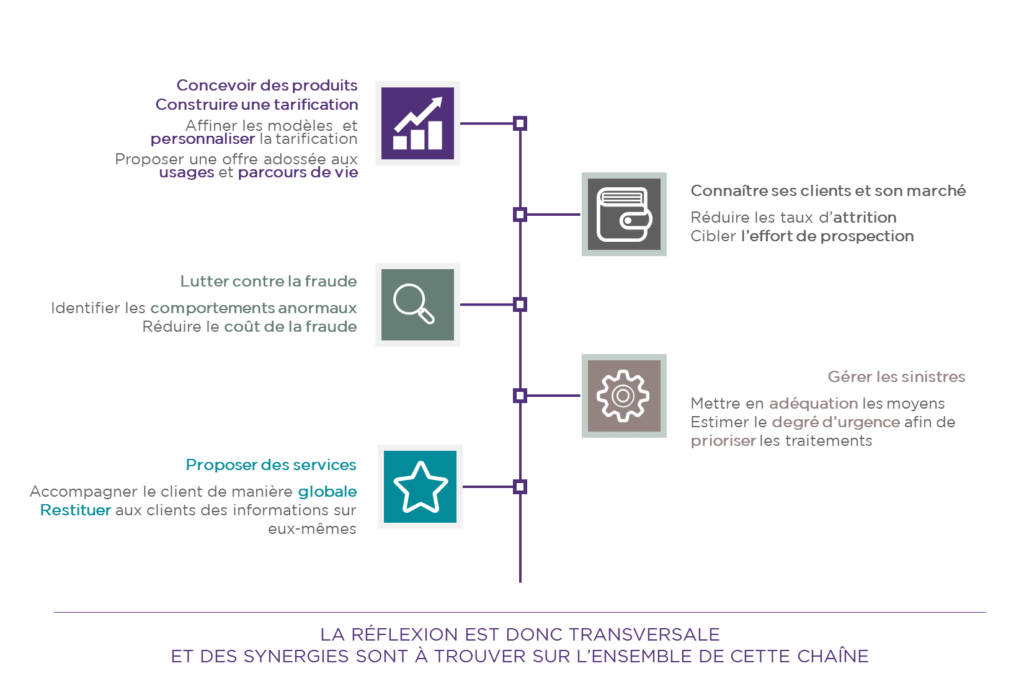
Depuis les mêmes sources de données, trouver une réponse aux besoins s’opère en simplifiant l’approche d’analyse à travers la recherche des grands moments de la vie des assurés tout en gardant une attention particulière sur les faux positifs. Concrètement, pour ce qui est des données, une même source peut servir à plusieurs usages et donc répondre à des besoins différents. La simplification de la recherche nécessite aussi une bonne connaissance des événements majeurs dans la vie de l’assuré afin de se positionner aux bons moments avec de nouvelles propositions de valeur et anticiper les changements du comportement client. À titre d’exemple, les données issues des réseaux sociaux peuvent être utilisées pour améliorer la connaissance client et ensuite réutilisées dans le cadre d’une démarche de lutte antifraude. Une déclaration d’accident faite par deux personnes amies sur Facebook peut laisser des doutes quant à la crédibilité de la demande. Autrement, en récoltant des cookies de navigation sur internet ou réseaux sociaux, prévoir les déménagements des clients revient à prévoir des résiliations de contrats d’assurance habitation et donc permettra d’orienter les actions marketing afin de réduire le churn.
Dans ce sens, la récolte d’information sur le client s’avère bénéfique pour l’assureur à condition que ce dernier puisse l’exploiter proprement et filtrer les faux positifs à travers une sélection adéquate des données à analyser. La sélection doit trouver son point de départ dans une vision exhaustive des sources de données possibles et leur intérêt pour les différents axes de la chaîne de valeur. En conséquence, les données ne doivent pas être utilisées par silos, mais de façon transversale afin de servir pour différents processus. D’ailleurs, la fonction du chief data officer est d’identifier les données pertinentes pour les différents métiers et d’aider à en trouver les cas d’usages.
… pour répondre à la menace des nouveaux entrants :
Plus qu’un enjeu, la transformation est à l’heure actuelle une nécessité pour les assureurs. Sans quoi, l’arrivée imminente des GAFA (Google, Apple, Facebook, Amazon) sur le marché ou encore les effets d’uberisation de l’économie vont redistribuer les cartes en faveur des acteurs ayant le plus de proximité et d’interactions avec leurs clients. En plus de leur expertise en analyse des données et leur capacité à catalyser des informations personnelles des utilisateurs contre des services à forte valeur ajoutée, les GAFA ont une capacité de diversification couplée à une grande puissance financière. D’ailleurs, Google a déjà investi 32,5 millions de $ dans la start-up innovante Oscar Health spécialisée dans l’assurance santé.
Mis à part les GAFA, d’autres acteurs optant pour un positionnement innovant peuvent aussi constituer une menace pour les assureurs traditionnels. La start-up The Climate Corporation, rachetée par Monsanto en est un bon exemple. Elle propose un nouveau modèle de service d’assurance destiné aux agriculteurs et leur propose de suivre un strict protocole agricole. The Climate Corporation est une plateforme technologique qui, à travers l’analyse des données agricoles et les simulations météo, aide les agriculteurs à améliorer leur activité et anticiper les risques météorologiques. Tout événement mal anticipé donne lieu à un dédommagement de l’agriculteur.
En somme, pour une sécurisation de leur activité, il convient aux assureurs de mettre le Big Data au service d’un repositionnement « disruptif » où on répond à des besoins en proposant de nouveaux produits et services.
La demarche Think big, try small:
Pour aborder la transformation et la valorisation des données, les assureurs ont tout intérêt à passer par une démarche innovante à petit pas pour laquelle les engagements financiers sont faibles et les résultats maîtrisés. De nombreuses sources de données sont disponibles, elles proviennent de données internes, objets connectés, réseaux sociaux, partenaires ou encore des organismes semi-publiques comme le SNIIRAM (système national d’information inter régimes de l’assurance maladie). Actuellement, ces sources sont peu ou mal exploitées. Pour parvenir à les valoriser et commercialiser de nouveaux produits adaptés à la rupture en cours, l’idéation doit suivre un processus itératif structuré en 4 grandes étapes.
Cartographier : Recenser les sources de données disponibles sans à priori
Pour pouvoir recenser de la manière la plus exhaustive possible les sources de données, il faut se baser sur des cas d’usages scénarisés. Et inversement, un recensement de l’ensemble des sources favorisera l’idéation des cas d’usage les plus disruptifs. Dans ce contexte, Solucom a mis en place le Creadesk afin d’accompagner ses clients au changement et favoriser l’émergence d’idées innovantes. Le Creadesk est, en effet, un ensemble de moyens (outils méthodologiques, lieux physiques ou virtuels et ressources humaines expérimentées) qui visent à favoriser la co-construction d’idées innovantes et le développement de POCs (Proof of Concept).
Cibler : Identifier et hiérarchiser les sources de données internes et externes
Une fois la cartographie des sources de données établie, la hiérarchisation des sources se fait selon deux niveaux d’analyse. Le premier niveau consiste en une priorisation au travers d’une matrice SWOT (Forces, Faiblesses, Opportunités & Menaces) pour chaque source de données. Le deuxième niveau consiste en une analyse plus fine dont l’objectif est de déterminer le degré d’exploitabilité puis ensuite le degré d’intérêt pour chaque source. Pour qualifier l’exploitabilité d’une source de données, il faut prendre en compte son accessibilité, ses coûts d’acquisition, sa structure et sa fiabilité ainsi que tous les risques réglementaires qu’elle présente. Ensuite, le degré d’intérêt, pour une source jugée exploitable, est qualifié en fonction de sa promesse de création de valeur absolue ou relative à un croisement avec d’autres sources. Ce dernier, est en effet, une résultante du premier niveau d’analyse et du degré d’exploitabilité qui permet de finaliser la sélection puis de classifier les sources de données.
Analyser : Analyser les opportunités offertes par les cas d’usage
Pour analyser les opportunités offertes par les cas d’usage, il faut établir une trajectoire de mise en place. Cette dernière est définie suite à une analyse des besoins en infrastructures, solutions technologiques et sourcing externe puis le plan de montée en compétence des équipes. L’intérêt de la trajectoire est donc de bien quantifier les efforts à fournir au regard des enjeux de développement pour ensuite choisir les cas d’usage prioritaires.
Élaborer : Définir et mettre en place les moyens techniques et humains pour réaliser les expérimentations
Une fois les cas pertinents choisis, cette étape consiste en une scénarisation détaillée selon les angles business model, marketing, juridique, techniques, parcours des données et impacts sur la gestion. Cette scénarisation permettra ensuite de préparer l’expérimentation à travers la mise en place de critères réussite, une plateforme d’expérimentation et des jeux de données confirmés prêts pour les tests.
Ci-dessous une illustration qui résume la démarche.
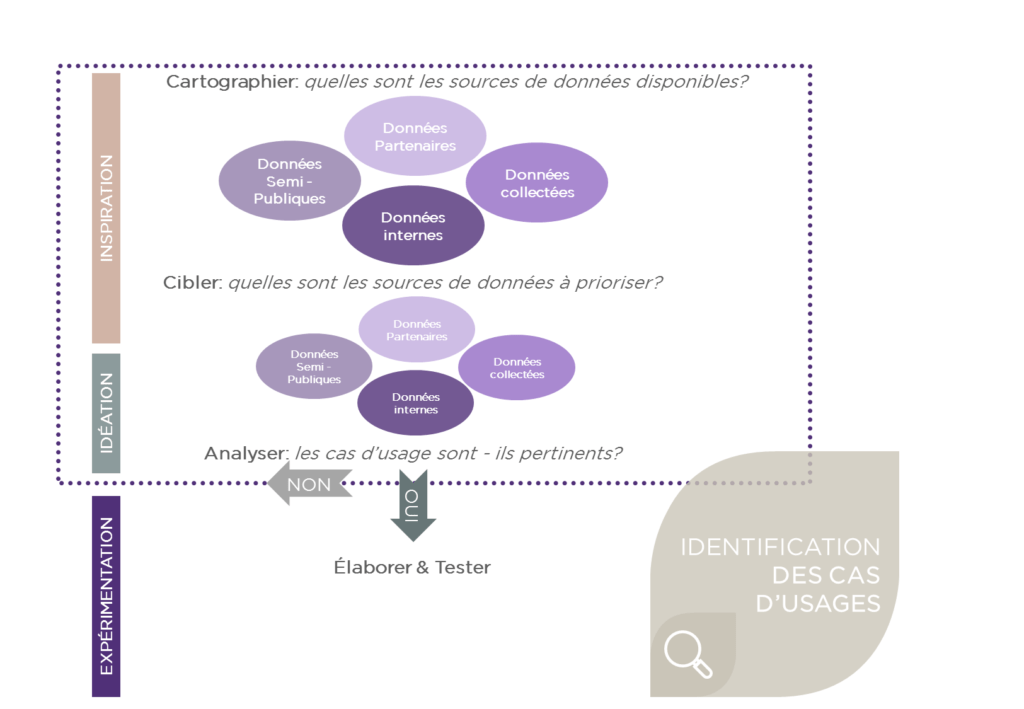
L’une des principales difficultés de l’exploration des données tient au fait qu’un certain nombre de données ou de sources n’auront pas d’intérêt séparément, mais en corrélation les unes avec les autres. Comparée au fonctionnement en silos actuellement en vigueur, cette démarche s’inscrit dans une logique d’innovation assumant le souhait de rupture avec les modes de fonctionnement traditionnels.
Au-delà du Big, le Smart
Au-delà du Big Data, l’approche Smart opte pour plus de pragmatisme vis-à-vis des données. Le principe fondateur de la démarche est, en effet, la co-construction avec les opérationnels d’une approche d’exploitation de l’actif informationnel interne dans un premier temps, puis externe dans un second temps tout en veillant sur le respect des données client. L’objectif étant de mettre les données au service des métiers, des clients et de l’entreprise en général, le projet Smart Data se doit d’être agile permettant ainsi d’effectuer une sélection restreinte des cas d’usage pertinents à expérimenter pour ensuite explorer le potentiel de valorisation des données pour chaque cas selon une logique Test & Learn.
Esprit d’un POC Smart
Une POC Smart prend la forme d’une mini-étude théorique suivie d’une expérimentation souvent à taille réduite dans le but de tester un concept ou vérifier une hypothèse. La démarche se déroule suivant des itérations entre l’exploration du potentiel des données disponibles et l’accompagnement de l’utilisateur. Dans un premier temps, on commence par la construction d’une base de données et l’étude de son contenu en fonction des besoins exprimés par les utilisateurs. Ensuite, on modélise les données et on construit des prototypes avant de lancer les expérimentations puis ajuster les prototypes en conséquence.
La démarche procède, comme illustré ci-dessous, par une multitude d’itérations techniques et fonctionnelles. Pour ce faire, il convient de maintenir l’agilité en conservant un esprit de start-up au sein des équipes et anticipant le futur pour accomplir d’éventuelles démarches industrielles.
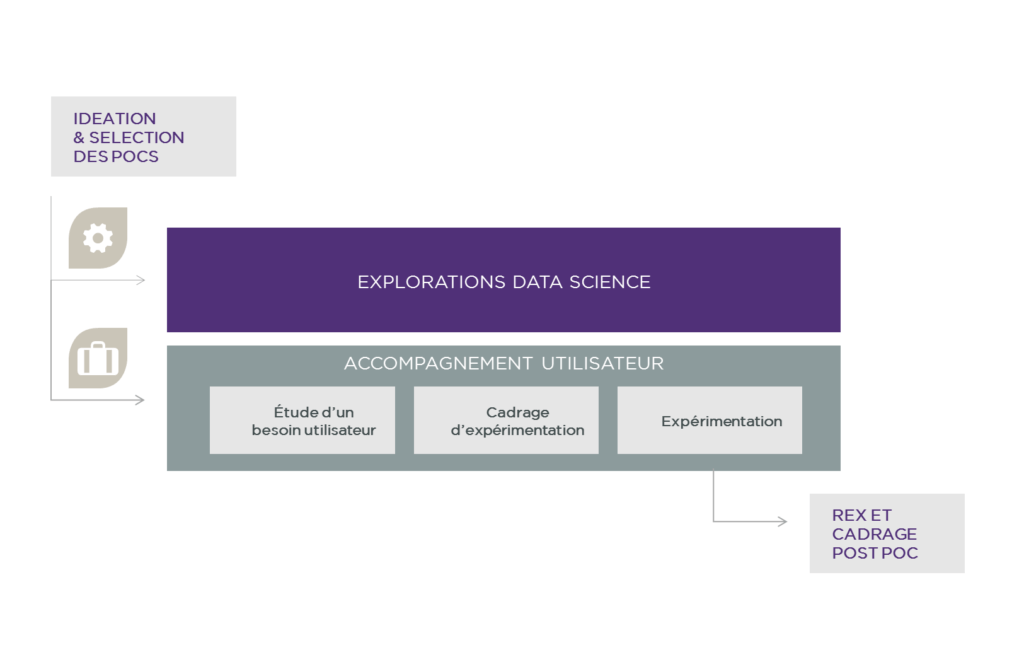
La valorisation des données est certes un enjeu de transformation pour les assureurs, néanmoins il ne s’agit pas d’un processus bien établi pour déclencher une certaine promesse de valeur. Il s’agit d’un projet où le pragmatisme est un véritable mot d’ordre. Les sources de données sont donc sélectionnées pour répondre de manière transverse aux besoins des opérationnels selon une approche agile. Les itérations permettront quant à elles de développer des cas d’usage concrets tout en ajustant la sélection des sources de données
Insights liés



